|
I am a Research Scientist at Meta AI in London, where I work on generative AI. My research focuses on diffusion and video foundation models, with an emphasis on multimodal conditioning and controllable generation. My long-term research focuses on advancing large-scale generative foundation models that are controllable, reliable, and adaptable across modalities. Before joining Meta, I received my Ph.D. in Computer Science from the University of Munich, where I was supervised by Prof. Dr. Volker Tresp and affiliated with the Munich Center for Machine Learning (MCML) and Siemens AG. Prior to that, I earned my M.Sc. in Computer Science from the Technical University of Munich, under the supervision of Prof. Dr. Volker Tresp and Prof. Dr. Stephan Günnemann. Email / Google Scholar / GitHub / Twitter / LinkedIn |

|
|
Diffusion Models · Video Generation · Multimodal AI · Generative Foundation Models · Controllable Generation |

|
Zijian Zhou, Shikun Liu, Haozhe Liu, Haonan Qiu, Zhaochong An, Weiming Ren, Zhiheng Liu, Xiaoke Huang, Kam Woh Ng, Tian Xie, Xiao Han, Yuren Cong, Hang Li, Chuyan Zhu, Aditya Patel, Tao Xiang, Sen He IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026 project page / arxiv A zero-shot reference-to-video generation framework trained only on video-text pairs, outperforming methods trained with explicit reference-video-text triplets on OpenS2V-Eval. |
|
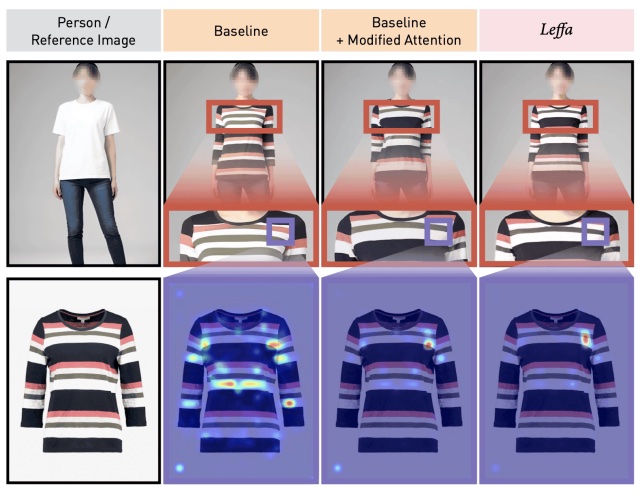
Zijian Zhou, Shikun Liu, Xiao Han, Haozhe Liu, Kam Woh Ng, Tian Xie, Yuren Cong, Hang Li, Mengmeng Xu, Juan-Manuel Pérez-Rúa, Aditya Patel, Tao Xiang, Miaojing Shi, Sen He IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025 code / arxiv A model-agnostic attention regularization that guides target queries to the correct reference region, reducing fine-grained texture distortion and achieving state-of-the-art virtual try-on and pose transfer. |
|
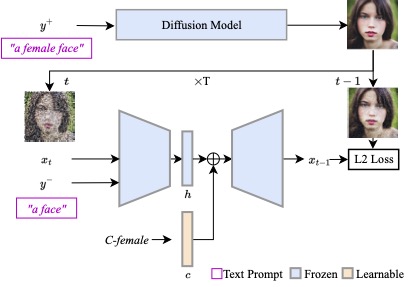
Hang Li, Chengzhi Shen, Philip Torr, Volker Tresp, Jindong Gu IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024 project page / code / arxiv Previous work interprets vectors in an interpretable latent space of diffusion models as semantic concepts. However, existing approaches cannot discover directions for arbitrary concepts, such as those related to inappropriate concepts. In this work, we propose a novel self-supervised approach to find interpretable latent directions for a given concept. With the discovered vectors, we further propose a simple approach to mitigate inappropriate generation. |
|
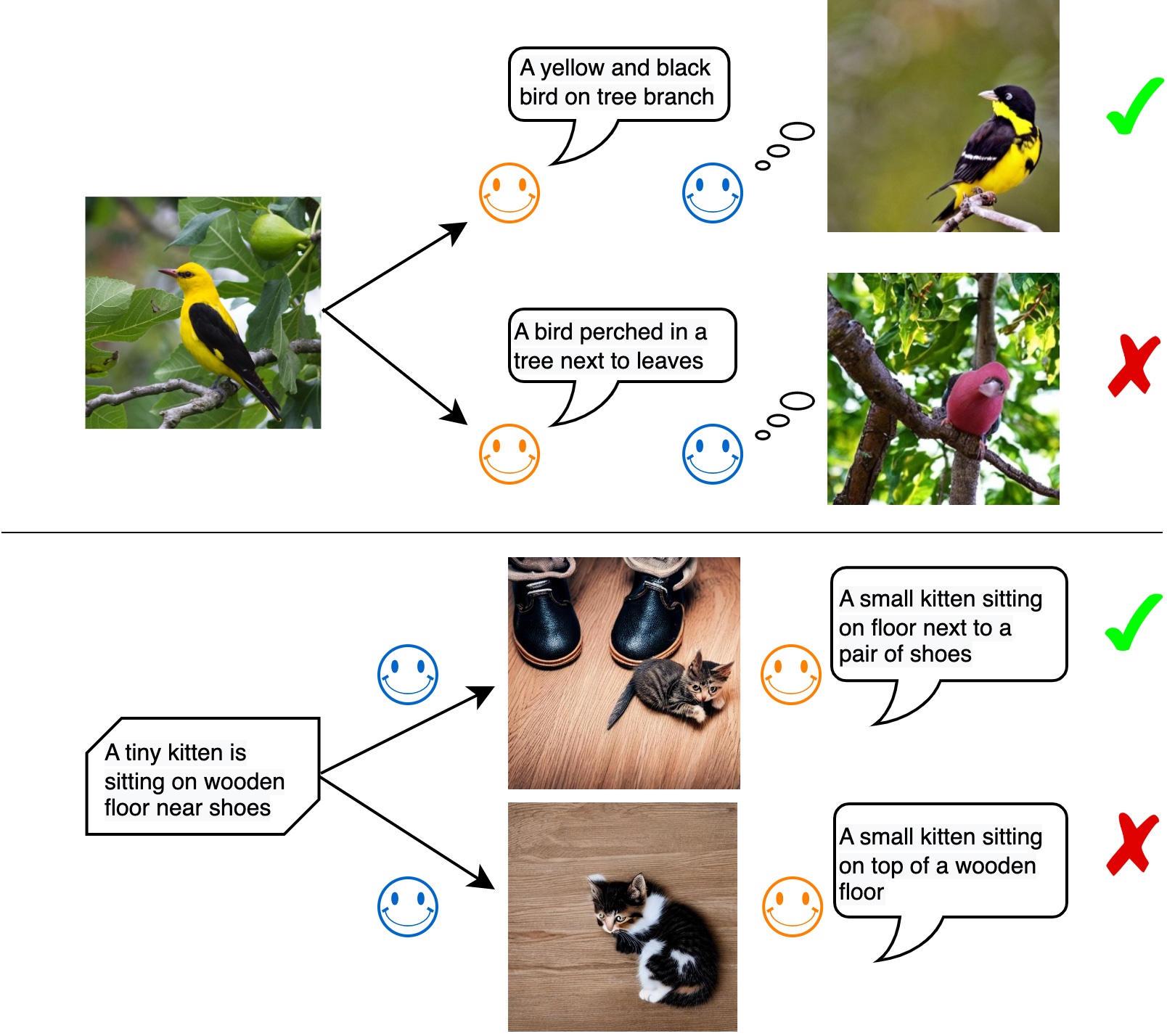
Hang Li*, Jindong Gu*, Rajat Koner, Sahand Sharifzadeh, Volker Tresp IEEE/CVF International Conference on Computer Vision (ICCV), 2023 project page / code / arxiv / cn blog We explore two types of large-scale multimodal generative models, image-to-text and text-to-image. The image-to-text model generates abstract descriptions of an image, whereas the text-to-image model decodes the text into low-level visual pixel features. These two models are closely related but their relationship is little understood. In this work, we study if large multimodal generative models understand each other. Specifically, if Flamingo describes an image in text, can DALLE reconstruct an image similar to the input image from the text? |
|
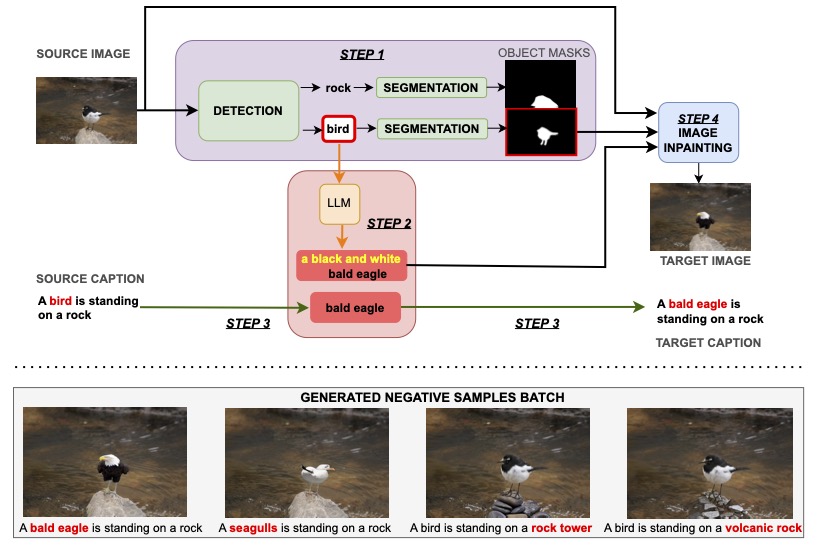
Ugur Sahin*, Hang Li*, Qadeer Khan, Daniel Cremers, Volker Tresp IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2024 project page / code / arxiv Leveraging generative hard negative samples, we significantly enhance VLMs' performance in tasks involving multimodal compositional reasoning. |
|
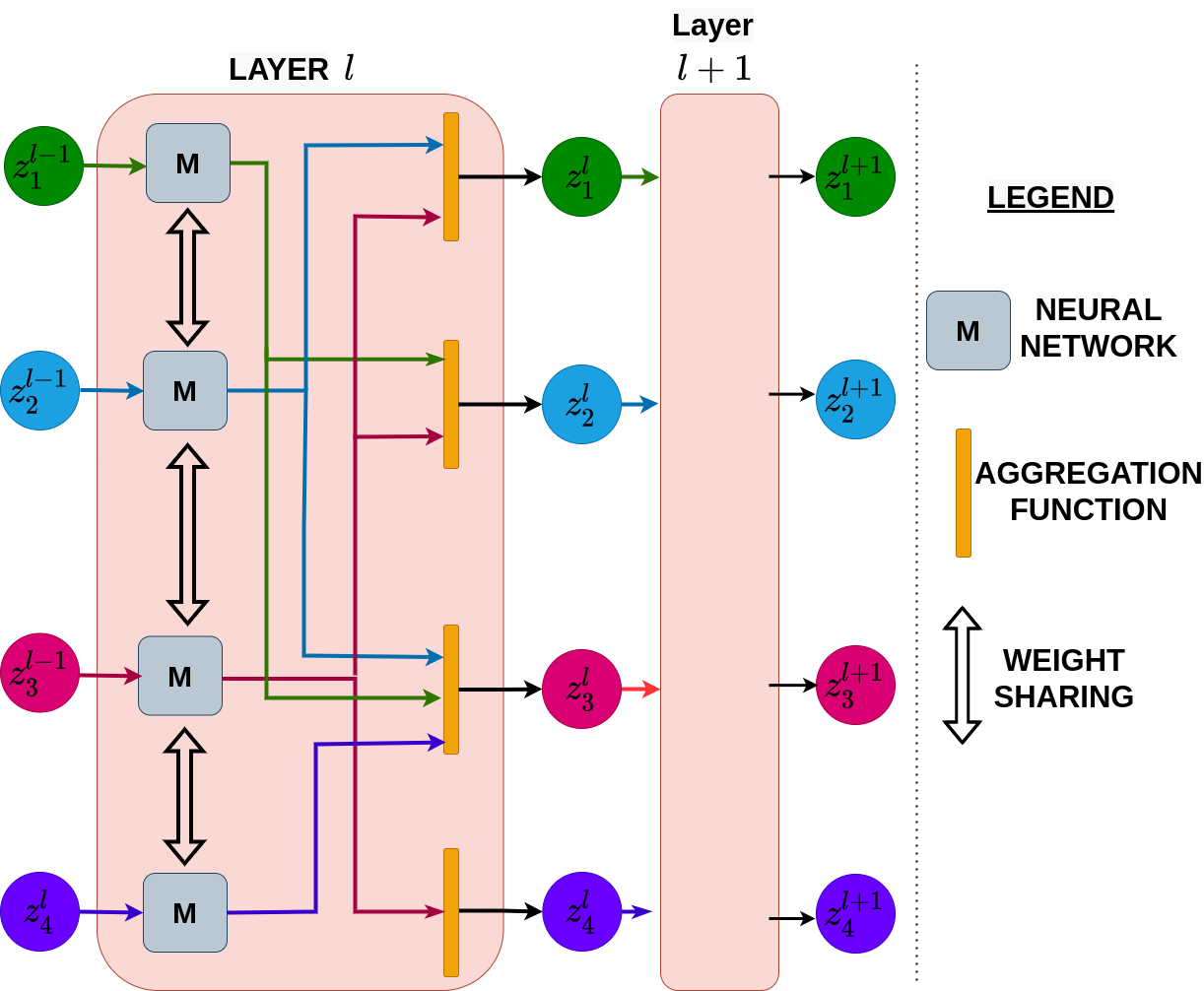
Hang Li*, Qadeer Khan*, Volker Tresp, Daniel Cremers Brain Informatics, 2022 code / arxiv In this paper, we take inspiration from attributes of the brain, to develop a computational framework to find the optimal low cost path between a source node and a destination node in a generalized graph. |
|
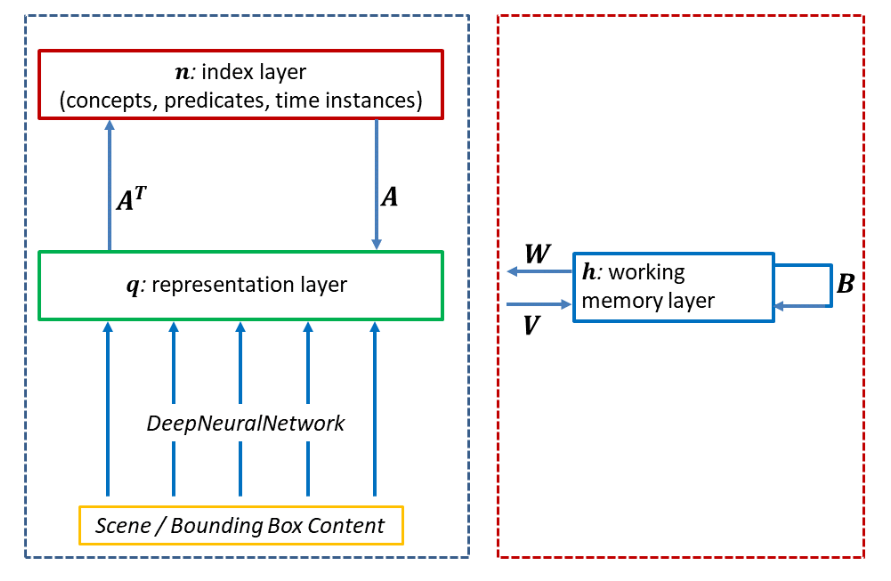
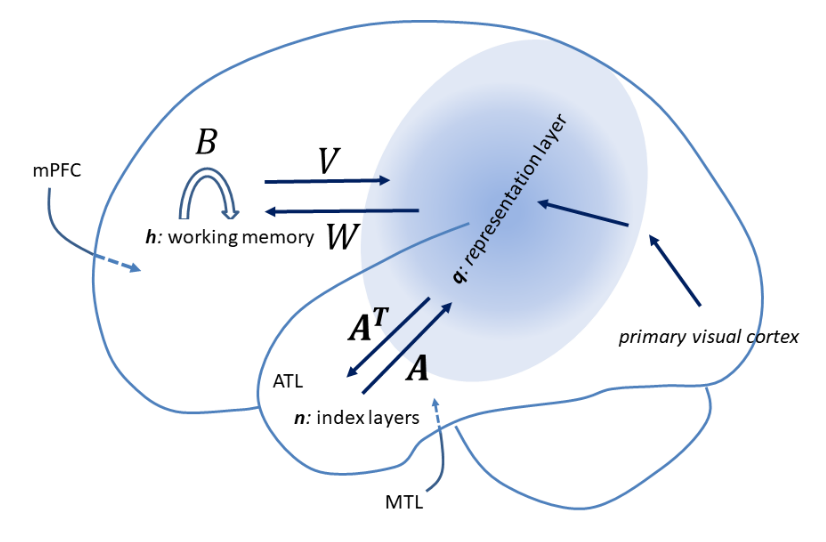
Volker Tresp, Sahand Sharifzadeh*, Hang Li*, Dario Konopatzki, Yunpu Ma Journal of Neural Computation, 2023 code / arxiv We present a unified computational theory of an agent’s perception and memory. Episodic memory and semantic memory evolved as emergent properties in a development to gain a deeper understanding of sensory information, to provide a context, and to provide a sense of the current state of the world. |
|
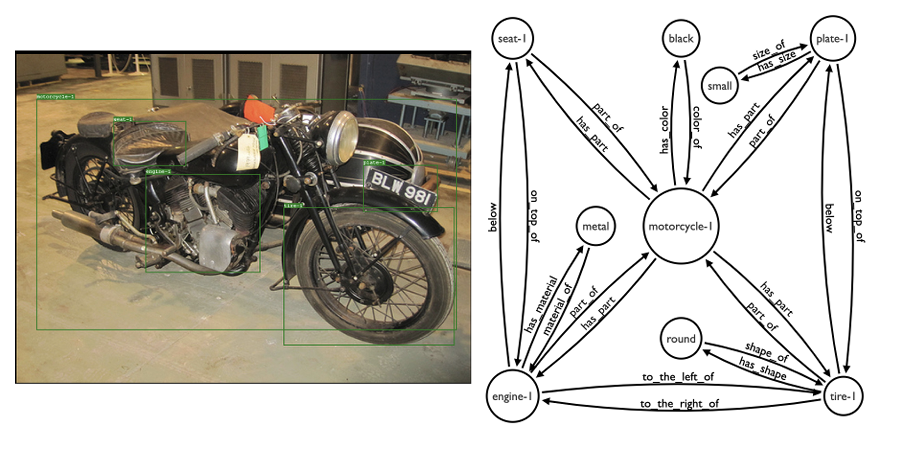
Rajat Koner*, Hang Li*, Marcel Hildebrandt*, Deepan Das, Volker Tresp, Stephan Günnemann ISWC, 2021 code / arxiv We find that Graphhopper outperforms state-of-the-art scene graph reasoning model on both manually curated and automatically generated scene graphs by a significant margin. |
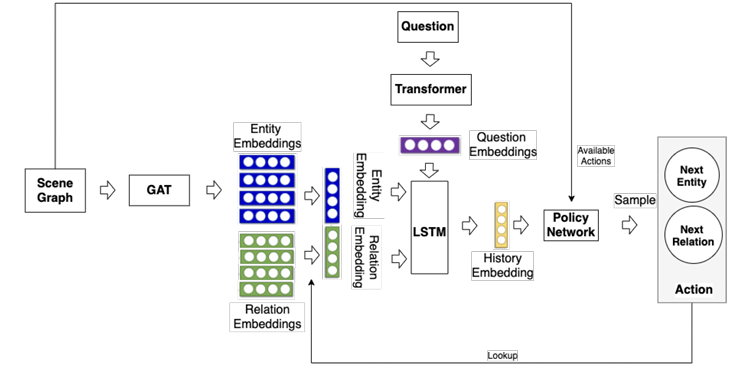
|
Marcel Hildebrandt*, Hang Li*, Rajat Koner*, Volker Tresp, Stephan Günnemann ICML Workshop, 2020 code / arxiv We propose a novel method that approaches the VQA task by performing context-driven, sequential reasoning based on the objects and their semantic and spatial relationships present in the scene. |
|
Last updated: May 2026
|